2025.02.14
意外と知らないPower Queryのユースケース12選
すぐに役立つPDFの読み込みから、データモデルの初歩まで
小西 宏明

これまで、Power Queryの基礎として「企業であまり使われていないPower Query(パワークエリ)の威力~Power Queryを活用した基本事項点検のススメ~」と、その応用として「Power QueryとPython in Excelとの相乗効果~Python in ExcelとPower Queryで実現する効率的なデータ処理~」を紹介した。Power Queryを利用することで可能となるデータ処理のうち、現場でニーズが非常に高いものの、著者の経験的に意外と知られていないと感じるものをピックアップし、ユースケース12選として提示する。未だExcel以外にデータ分析の武器を持たない企業も多い中、本稿はデータ活用の進展に即効性のある内容に的を絞った情報提供を狙いとする。
はじめに
本稿の前段として、「企業であまり使われていないPower Query(パワークエリ)の威力~Power Queryを活用した基本事項点検のススメ~」と題した記事を掲載した。ExcelのPower Query[1]とはどういうものでどのような利点があるのかは、当該の記事やMicrosoftによる機能説明[2]などを併せてご覧いただきたいが、元データを破壊する心配をせずに試行錯誤できること、処理の過程が残りトレーサビリティがあること、Excelの104万行の制約を超えてピボットテーブル・ピボットグラフの集計、分析機能を利用できるメリットが代表的である。
本稿では実務に即効性があるユースケースについて、その概要と簡単な操作概要を画面のイメージ付きで解説する。ユースケースは、著者がさまざまな場面で社内外の方に紹介する中で、特に反響があったものを厳選している(若い番号ほど、初めて知ったときにインパクトが大きい傾向にあると考えている)。なお、ここではPower Queryの具体的な操作方法にはごく簡単にしか触れないため、詳細はMicrosoft Support等を参照いただきたい。
ユースケース12選
1. PDFファイルからのテーブル取り込み
まずは、特に作業時間の短縮効果の大きいPDFデータの読み込みについて紹介する。簡単な内容でありながら効果が大きく、これまでさまざまな場面で折に触れ紹介してきた際、人によっては非常にインパクトが大きいようであるため最初に触れることとした。
図1のように、PDF内に埋め込まれた表形式のデータの分析に手間を要した経験はないだろうか。著者が見たところ、こうしたファイルのデータを分析する際には、コピーアンドペーストや、転記を行っている方も少なくないようだ。ここで、Power Queryを使えば、PDFにテーブルデータが含まれる場合もPDFファイルを直接読み込んでテーブル化が可能である。PDF 内に表形式で格納されているデータを抽出し、自動的に Excel のテーブルとしてインポートできる(注:基本的に標準具備されている機能であるが、バージョンが古い場合には、利用できない場合もある)。
なお、[Webから]を用いてURLを指定すれば、Webサイト上の表形式のデータ(PDFファイル含む)を読み込める場合がある。
主な操作:
- [データ] タブ → [データの取得] → [ファイルから] → [PDF から] を選択(図2)
もしくは[データ] タブ → [データの取得] → [Webから] → 当該PDFのURLを入力 - PDF 内の抽出可能なテーブル一覧が表示されるので、必要なテーブルを選択
- 列名や行の構成をチェックし、不要な行や列は削除のうえ、データ型を整形して出力(図3)
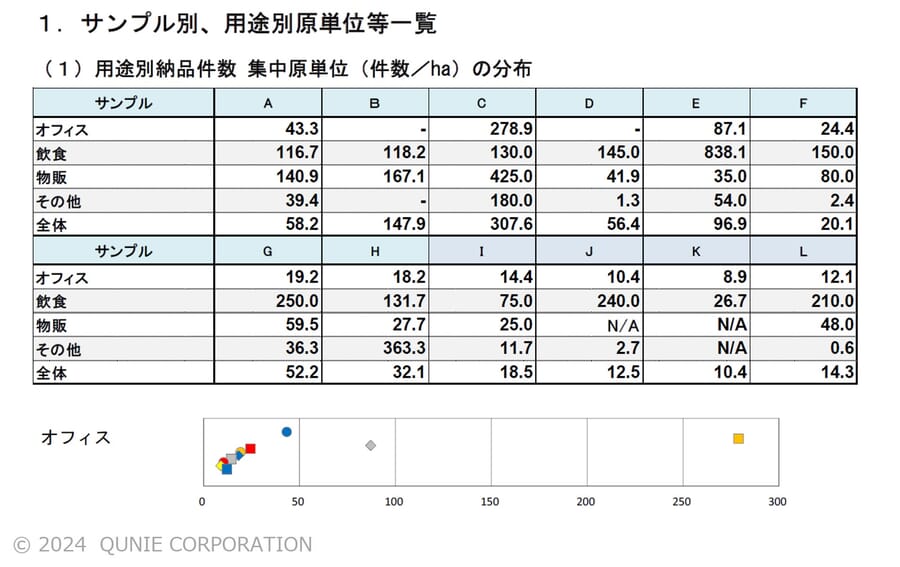
図1:表形式のデータを含むPDFファイルの例
( サンプル画像は[3]の国土交通省の公開データを基に著者作成)
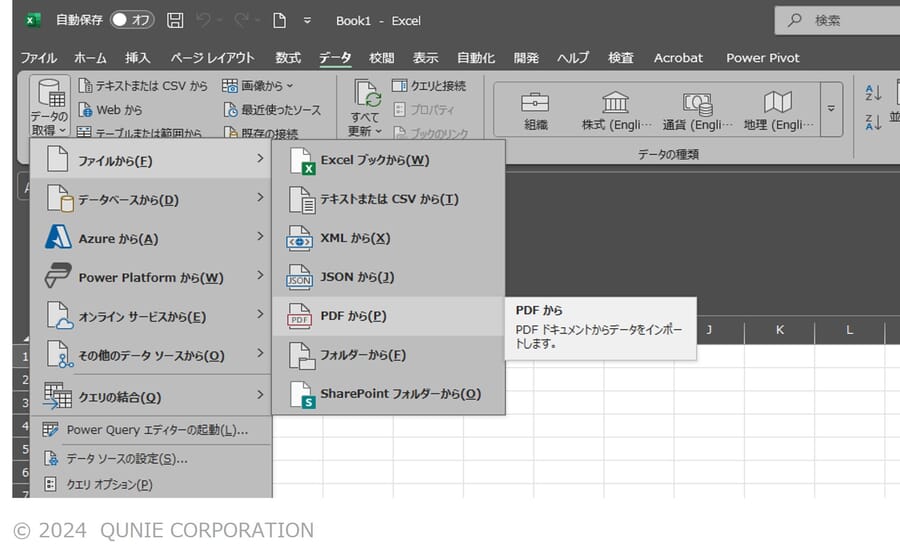
図2:Power QueryにおけるPDFファイル読み込みの入り口(著者作成)
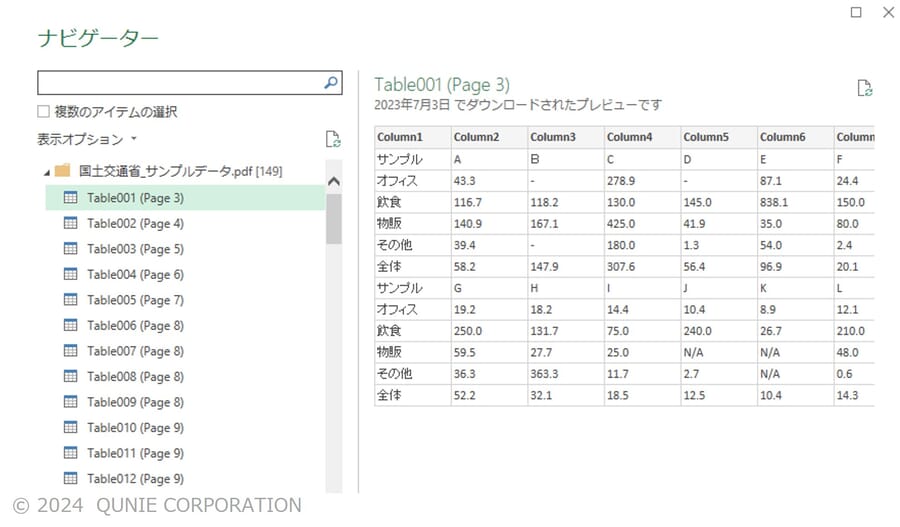
図3:表形式のデータを含むPDFファイルのインポート結果プレビュー例
(サンプル画像は[3]の国土交通省の公開データを基に著者作成)
ぜひ必要に応じてこの機能を積極的に活用し、作業時間短縮を図られたい。この手法が適用可能なデータである場合、手打ちで入力している方にとっては非常に効果があるであろう。
2. データの素性チェック(分布、基本統計量、エラー有無等の把握)
図4のように、Power Queryエディタ内で、データのプレビューで表示する内容の選択ができる。この機能はデフォルトではOFFになっている(チェックボックスのチェックが入っていない)ため初期状態では表示されないことに注意が必要だ。ここで表示させたい項目(「列の分布」「列の品質」等)を選択することで、各列におけるデータの分布やエラー有無、簡単な統計情報等を確認できるようになる(図5)。
主な操作:
Power Queryエディタ内の[表示] タブ → [データのプレビュー]内のチェックボックスを押下
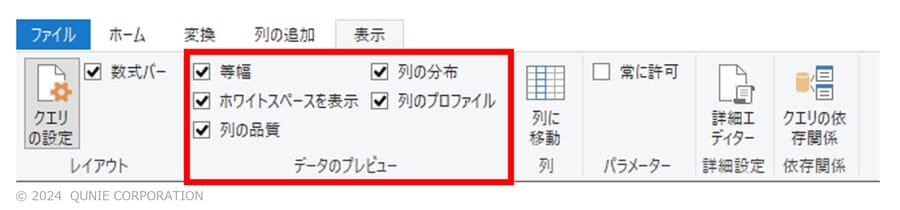
図4:Power Queryエディタ内の[表示]タブ内の[データのプレビュー](著者作成)
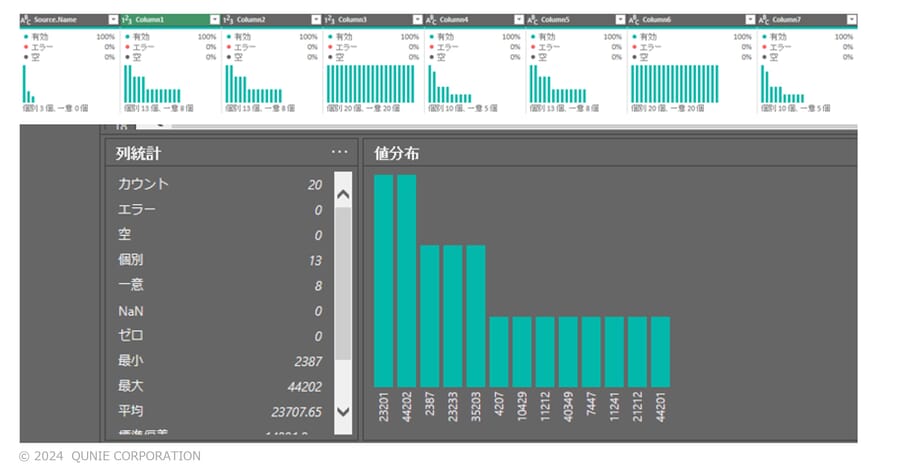
図5:選択した値の分布、列統計等の表示
(サンプル画像は[3]の国土交通省の公開データを基に著者作成)
3. フォルダごと一括でファイルを読み込む
同じ形式のファイルを定期的に受け取る場合などに、同じ形状(列名が同一であることが重要)をした複数のファイル(日ごとに取得しているCSVファイル等)(図6)をまとめて読み込み、縦結合(アペンド)して、一覧表として1つのデータに統合できる。これにより、手動でデータを統合する手間を削減可能だ。繰り返しとなるが、原則として各ファイルの形状が一致していることが必要である。
主な操作:
- [データ] タブから [データの取得] → [ファイルから] → [フォルダから] を選択(図7)
- 統合対象ファイルのフォルダを指定し、テーブルとしてインポート(図8)
- 列名のリネームや不要列の削除などの前処理を行い、1つにまとめる
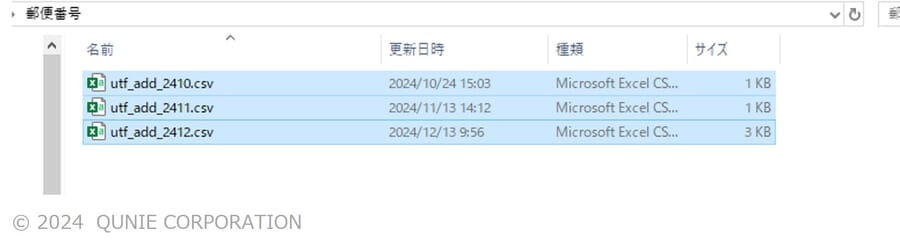
図6:同じ形式のファイルが集まったフォルダの例
(サンプル画像は日本郵便「郵便番号データダウンロード」[4]のデータを基に著者作成)
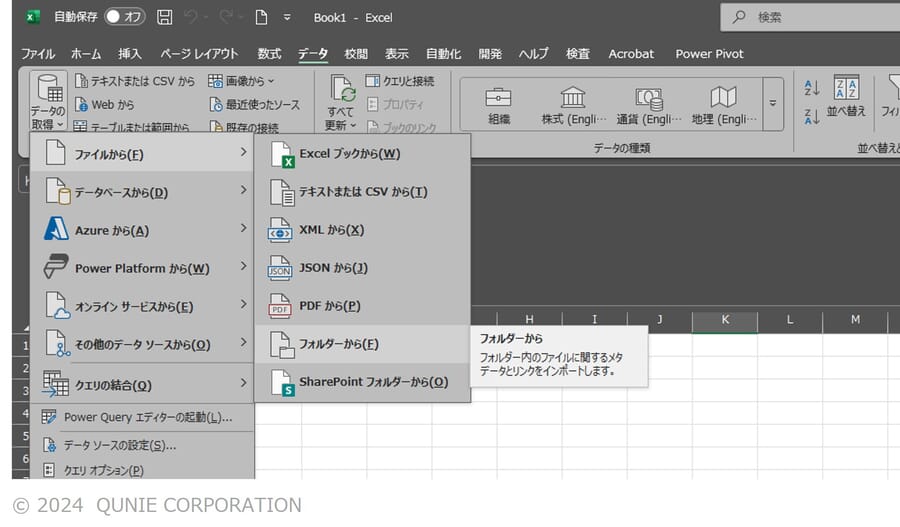
図7:フォルダからファイルを読み込む(著者作成)
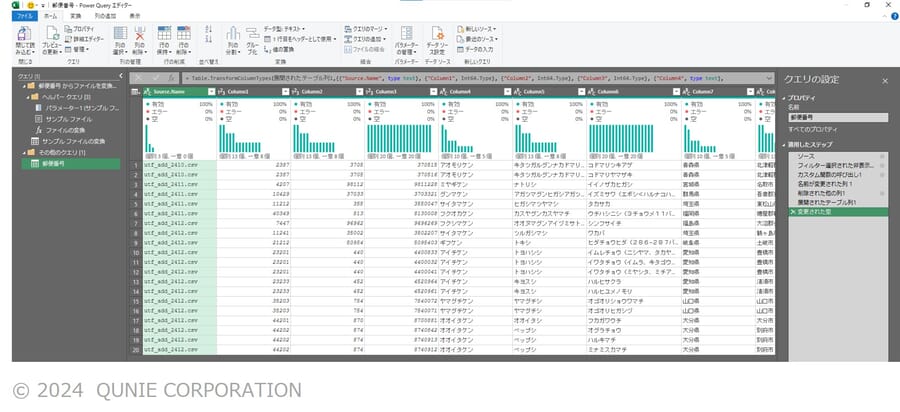
図8:同一フォルダ内の3ファイルを読み込んだ例。最も左の列にはファイル名が表示されている
(サンプル画像は日本郵便「郵便番号データダウンロード」[4]のデータを基に著者作成)
なお、フォルダ内のファイルが増えた際には、更新ボタンを押下すれば読み込んで自動集計ができる。PCのスペックにも依存するが、この機能を用いて数百のファイルを扱うユースケースも可能となる。もしこの機能を知らなければ、Python等を駆使してもかなりのスキルと工夫を要するため、同様の効率化はなかなか実現できないであろう。多数の同一形状のファイルを扱うに際して、非常に有力な選択肢であるため、ぜひ、あてはまるケースにおいては活用を検討されたい。
4. 異なるデータソースの結合・マージ
Excel シートとデータベース、あるいはテキストファイルなど、異なるソースのデータを縦結合や横結合(マージ) して分析に活用することができる。もしこの機能を知らなければ、必要なデータを全てExcelのシート上に転記して、VLOOKUP関数等で結合を行うことになるが、それに比べてシステマティックに処理を進めることができるため非常に有効である。あわせて、データをどこから読み込んで、どのように結合したのかを、エディタ内のプレビュー画面([クエリの依存関係])にて図式化することもできるため、見通しが良い。
主な操作:
- Power Query エディタで [ホーム] → [クエリのマージ] を選択
- 共通のキーとなる列を指定し、VLOOKUP のような感覚で参照先テーブルから列を取り込む
- 結合方法(左外部結合など)を選び、必要なデータを結合
- [クエリの依存関係]でデータ結合までのデータの流れを確認(図9)
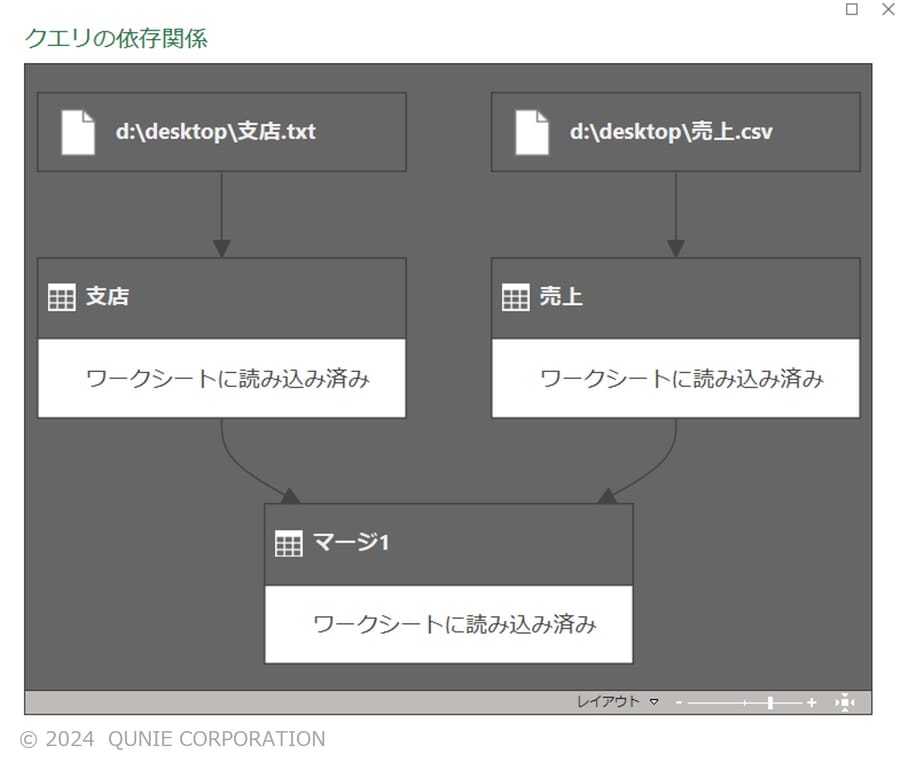
図9:テキストデータとcsvデータでのマージ
(架空データを基に著者作成。なお、クエリの依存関係はPower Queryエディタの[表示]タブ内の[クエリの依存関係]から閲覧可能)
5. データクレンジング(不要な行・列の削除や重複排除、欠損値処理)
データに重複レコードがある、あるいは欠損値が含まれている場合に重複を削除したり、欠損を一括置換したりすることで、分析に適したクリーンなデータを得られる。これらは通常のExcel機能でももちろん可能ではあるが、処理の過程が残らないこと、データを誤って壊してしまう恐れなどがある。その点、Power Queryを用いれば、全ての処理の履歴が残り、かつ必要な時にはいつでも処理を直せる。特に、不要な列の削除により、フォーカスしたい列だけにデータを絞れるのが便利であり、かついつでも列の削除は元に戻すことができる。そして、これらは全て、元データには一切影響を与えないことがポイントである。
主な操作:
- Power Query エディタで[変換] → [重複の削除] を使い、一意のデータに絞る
- 欠損値(nullなど)を他の値や空白に置き換える
- [ホーム] → [列の削除] や [行の削除] オプションを利用し、あらかじめ不要な行・列を除去
6. データ型の自動変換・統一
文字列として取り込まれた日付や数値を、正しいデータ型(Date/Numberなど)に変換しておくことで、後続の計算やピボットテーブル作成のトラブルを減らせる。例えば、日付のデータはあらかじめ明示的に日付型にしておくことで、ピボットテーブルではグループ化の機能が働く。(テキスト型では働かない)ピボットテーブルとPower Queryを必要に応じ往復しながら、意図した集計・分析ができるよう工夫していくことが望ましい。
主な操作:
- Power Queryエディタ上では、取り込んだ列のデータ型が “abc” や “123” のアイコンで表示される
- [変換] → [データ型] から適切な型を選択
- 日付型など、必要な型指定をPower Queryの段階で済ませておく
7. ロジックを再利用したデータ更新
同じ形式(同じ列数、同じ列名)のファイルを定期的に受け取る場合、Power Queryでフォルダ、ファイルを指定し、新しいファイルを自動的に取り込みできる。ファイル名が同一のまま更新された場合には更新ボタンを押下するだけでデータが更新される。また、ファイル名が変わった場合にはパスを変更して更新ボタンを押下して処理を回しなおせばよい。
主な操作:
- ファイル名が変わった場合には、Power Queryエディタ上の[適用されたステップ]の[ソース]における歯車のマークをクリック → ファイルパスを設定
- ファイルが同一名称のまま更新された際には [更新] だけで自動集計
8. 文字コードがShift-JIS以外のデータの読み込み
Excelでは、Shift-JIS以外の文字コードのデータを含むファイルをそのまま開くと文字化けする(図10)。Power Queryで文字コードを指定して読み込む(図11)ことで、これを回避できる。
主な操作:
- [データの取得]からデータを読み込み
- ポップアップウィンドウ内のタブで文字コードを指定
なお最新のExcelでは、自動的に文字コードを判別してくれる機能が標準具備されている。その機能がないバージョンの場合、あらかじめメモ帳等のテキストエディタでファイルを開き、文字コードを確認しておく必要がある(図12)。なおPower Queryからは脱線するが、メモ帳で文字コードを確認できることを知らない方も多く見受けられるため、参考にされたい。
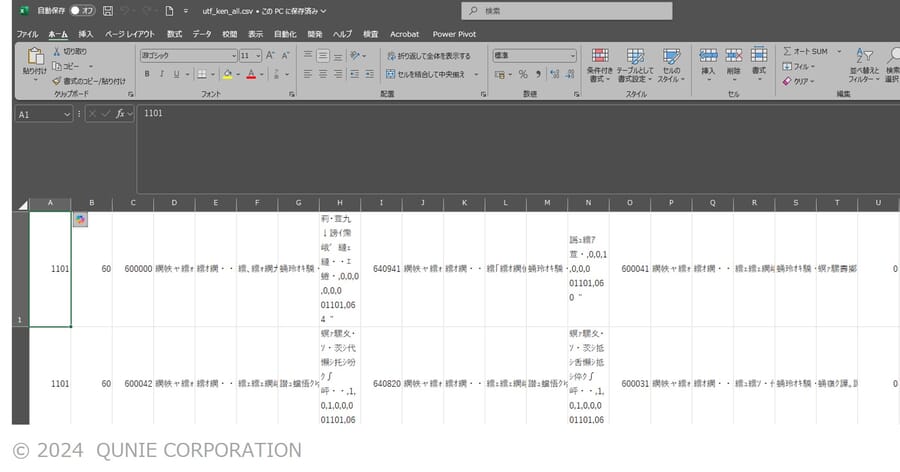
図10:文字コードがUTF-8のcsvファイルをそのまま読み込んだ場合の文字化け
(サンプル画像は日本郵便「郵便番号データダウンロード」[4]のデータを基に著者作成)
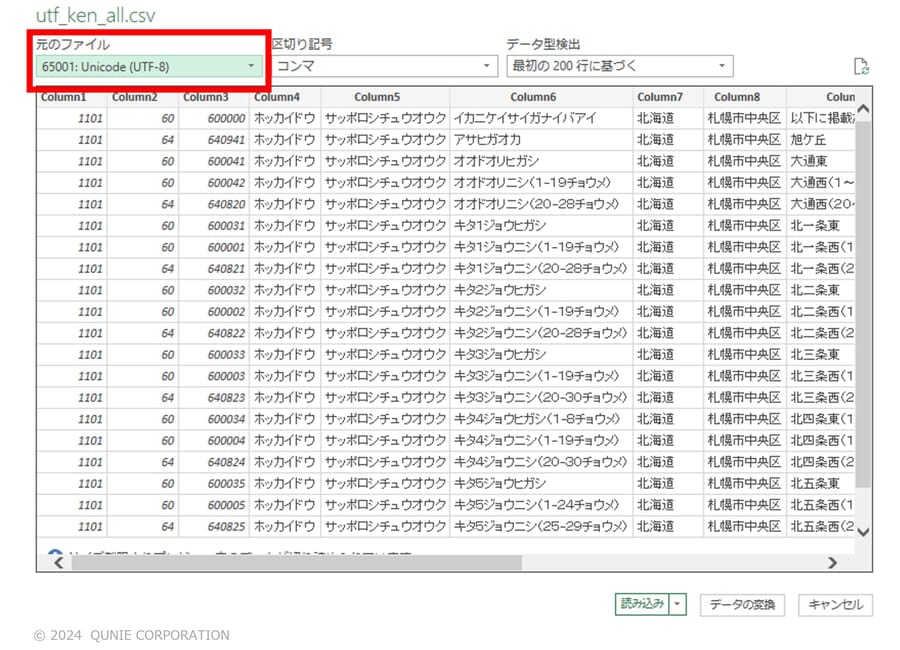
図11:文字コードの指定読込み
(サンプル画像は日本郵便「郵便番号データダウンロード」[4]のデータを基に著者作成)
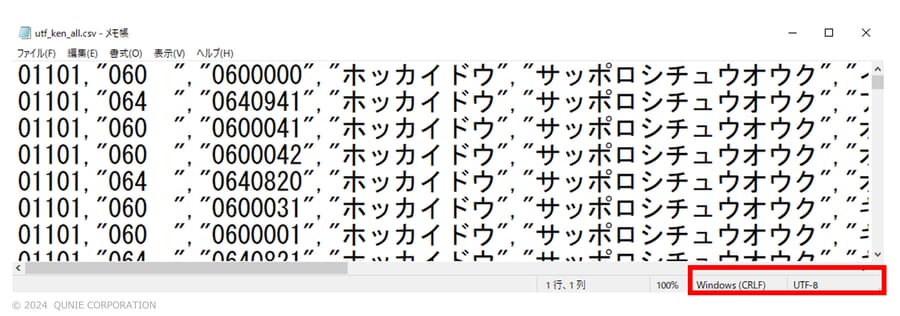
図12:テキストエディタでの文字コードの事前確認例。画像はメモ帳での例
(自動認識がないExcelの場合に必要)
(サンプル画像は日本郵便「郵便番号データダウンロード」[4]のデータを基に著者作成)
9. クロス集計表における列のピボット解除
クロス集計表において、Power Queryで処理したうえでピボットテーブル・ピボットグラフを作成すると、集計・分析が容易になる場合がある。図13のクロス集計された表を例にとると、そのままでは「月」のフィールドが複数生成されてしまい、ピボットテーブル・ピボットグラフの作成に向かないことが分かる。
こうした場合、図14のように、Power Queryで[列のピボット解除]を用いて、データの持ち方を変換することで、通常のテーブル形式に戻し、分析やグラフ化がしやすい状態に整形することが有効である。
主な操作:
- Power Queryエディタで[変換] → [列のピボット解除] を選ぶ
- 列見出しになっている月ごとの値などを1列にまとめ、行指向分析やグラフ作成がしやすい構造に変換(図14)
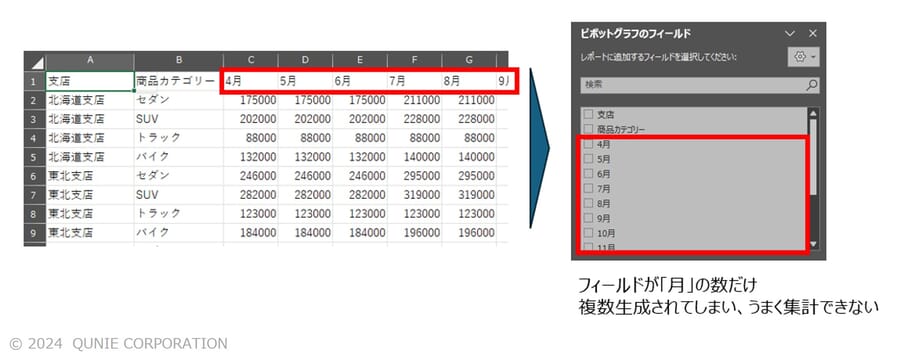
図13:「支店」と「商品カテゴリー」でクロス集計された表
(架空データを基に著者作成)
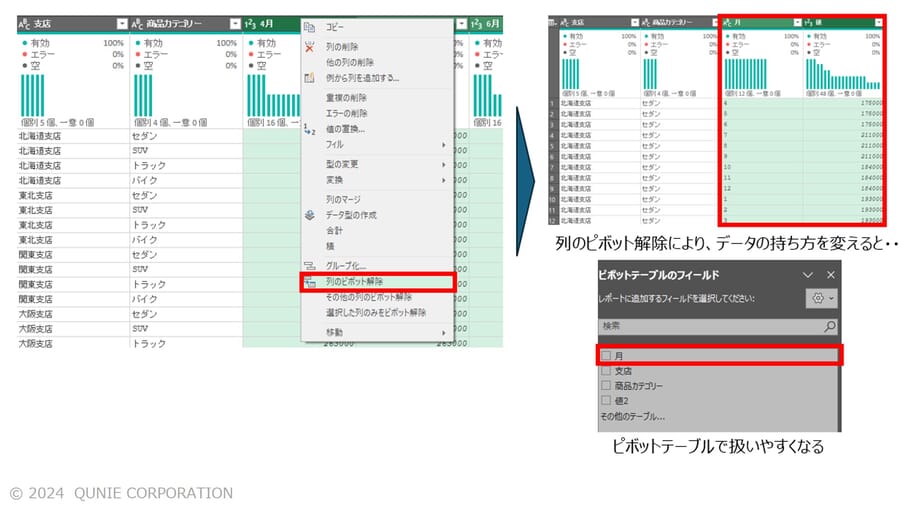
図14:[列のピボット解除]で「月」を1つのフィールドにまとめると扱いやすい
(架空データを基に著者作成)
10. セル結合への対応(フィル)
Excelのデータを扱う際に、結合されたセルが含まれていて難渋した経験のある方は少なくないだろう。セル結合では、結合されている複数のセルのうち1つにしか、実際にはデータが入っていない。このことが、ピボットテーブル等で集計を行う際にハードルとなる。
こうしたセル結合されたテーブルデータについては、Power Queryによる処理で、データが入っていないセルを充足したうえで集計・分析を進めると有効な場合がある。具体的には、フィル機能を使うことで、セル結合前のデータが埋まっていなかったセルを埋めることができる場合がある。フィルというと、馴染みのない方が多いと思われるが、これが当てはまる場面では、非常に強力な機能であるので是非試して欲しい。
主な操作:
- Power Queryエディタで[変換] → [列のピボット解除] を選ぶ
- セル結合を含む列の上で右クリックし、[フィル] → [下へ] もしくは [上へ] をクリックし、データを充足させる(図15)
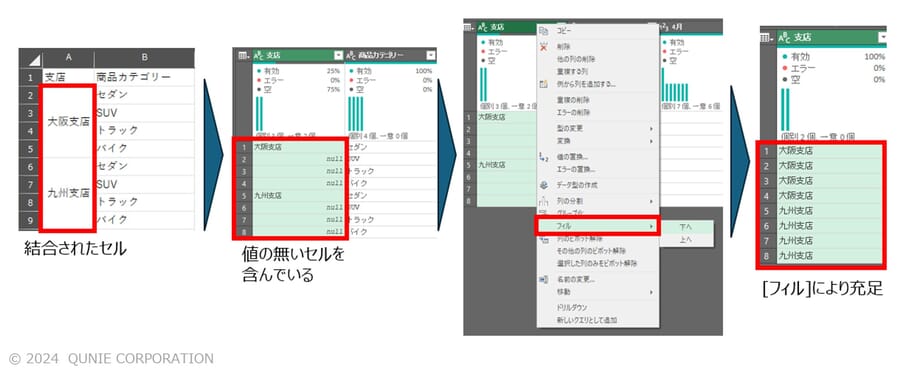
図15:結合されたセルのなかに存在する空白セルをフィルで充足
(架空データを基に著者作成)
11. 日付テーブルやマスタテーブルの取り扱い
売り上げデータなどを扱う際、日付テーブルや製品マスタテーブルを Power Queryで読み込んでメンテナンスしておき、分析時に結合させると便利だ。通常のExcelでこれを行う場合にありがちなのは、気づかないうちにマスタテーブルの個別のセルを触ってしまいデータを壊してしまう初歩的なトラブルや、マスタテーブル内のレコード重複に気づかないことである。Power Queryでマスタテーブルを扱えば、不意にデータを壊す心配はなく、また、重複は容易に検出・削除することができるため、処理の整合性を保ちやすい。
主な操作:
- [新しいクエリ] で空のテーブルを作成し、M言語(Power Query式)で日付の範囲を生成
- マスタテーブルも同様に Excelや CSVから取り込み、変更があったら即更新
12. Power Pivotによるデータモデルの作成と活用
Excelのワークシートに読み込むことのできない104万行を超えるデータであっても、「接続のみ」、「データモデル」にチェックを入れた状態で読み込みを行える。これにより生成されたデータモデルを利用してピボットテーブル・ピボットグラフ作成を行うことができる。このことは、最初の記事でも触れた。
これによるメリットは、単に大量のデータが読み込めることだけではないことに言及しておきたい。
104万行以下のデータであっても、集計・分析の幅が大きく広がるというメリットがある。具体的には、データモデルを基に作成したピボットはPower Pivot[5]と呼ばれ、DAX[6]を使用して計算列とメジャーのカスタム計算を定義することができる。例えば、特定の条件に基づいた合計や平均を計算することができる。DAXはExcelの数式に似ているため、比較的馴染みやすいのも利点である。また、多くのBIツールと同様、テーブル間のリレーションを作成することもできる。
Power Queryだけでなく、Power Pivotについても有用であるにも関わらず、多くの企業の実務担当者の間での認知度は低いと感じる。今後、別途記事で触れることを検討したい。
主な操作:
- [データの取得]からデータを読み込み
- Power Queryエディタ上で編集
- [閉じて次に読み込む]で[接続のみ]を選択し、[データモデル]にチェックを入れて読み込む
- データモデルが作成される
- ピボットテーブル・ピボットグラフの挿入を行う。この際、[このブックのデータモデルを利用する]にチェックを入れておく
- 通常のピボットテーブル・ピボットグラフと同じ要領で集計・分析
- 必要に応じ[データモデル]を利用したピボット(Power Pivot)でメジャーを作成し集計・分析(図16)
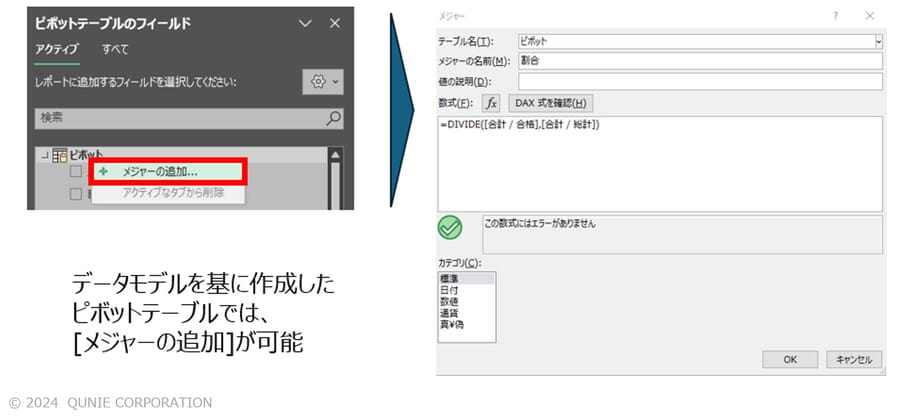
図16:データモデルから作成したピボットテーブルにおけるメジャーの作成イメージ
(架空データを基に著者作成)
おわりに
データ活用では「良い仮説、良いデータ、良い処理」が重要である。今回は前回までの記事に引き続き「処理」にフォーカスし、Power Queryのユースケースのうち、実務上の効果が高いと思料されるものをピックアップして紹介した。
これまで紹介したPower QueryやPython in Excel、Power Pivotなどにより、多くの企業の実務担当者が認識している以上に、Excelでできることの幅は広がっている。何ら特別な準備(環境構築)をすることなく、これらのデータ活用が可能となることが朗報に感じる方も多いのではないだろうか。まだ使用したことのない方は、ぜひ学習や実務での活用にトライいただきたい。
- [1] Microsoft(2025), “Power Query とは”, https://learn.microsoft.com/ja-jp/power-query/power-query-what-is-power-query (参照日2025年1月31日)
- [2] Microsoft(2025), “ExcelのPower Queryについて”, https://support.microsoft.com/ja-jp/office/excel-%E3%81%AE-power-query-%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6-7104fbee-9e62-4cb9-a02e-5bfb1a6c536a (参照日2025年1月31日)
- [3] 国土交通省総合政策局物流政策課(2025), “サンプルデータ集”, https://www.mlit.go.jp/common/001178227.pdf(参照日2025年1月31日)
- [4] 日本郵便株式会社(2025), “郵便番号データダウンロード”, https://www.post.japanpost.jp/zipcode/download.html(参照日2025年1月31日)
-
[5]
Microsoft(2025), “Power Pivot - 概要と学習”, https://support.microsoft.com/ja-jp/office/power-pivot-%E6%A6%82%E8%A6%81%E3%81%A8%E5%AD%A6%E7%BF%92-f9001958-7901-4caa-ad80-028a6d2432ed
(参照日2025年2月13日) -
[6]
Microsoft(2025), “PowerPivot における Data Analysis Expressions (DAX)”, https://support.microsoft.com/ja-jp/office/powerpivot-%E3%81%AB%E3%81%8A%E3%81%91%E3%82%8B-data-analysis-expressions-dax-bab3fbe3-2385-485a-980b-5f64d3b0f730
(参照日2025年2月13日)



あわせて読みたい
-

2023.10.23
企業であまり使われていないPower Query(パワ…
Power Queryを活用した基本事項点検のススメ
小西 宏明
- DX
- データマネジメント
- 省人化
-

2024.12.19
Power QueryとPython in Excel…
Python in ExcelとPower Queryで実現する効率的…
小西 宏明
- DX
- データマネジメント
- 省人化
-

2023.12.18
概念データモデルから始める真にデータドリブンな製造業DX
自社の全てをデータで語る
武井 晋介
- DX
- ERP
- データマネジメント
- デジタライゼーション
- 製造業
-

2024.03.21
売れる製品を創るデータ分析と見積改善
顧客心理の変化を捉える、見積業務改善の効果創出方法
岡本 典浩
- CX
- 製造業