2023.11.09
“IT素人”で進める製造業のデータ利活用
統合クラウドデータ基盤の潮流とデータ民主化
五十嵐 洋樹

製造業各社において、「データ利活用」はデジタルトランスフォーメーション(DX)推進の中心となる施策の1つであるが、失敗に終わってしまうケースも散見される。本稿では、これらの原因や今後目指すべきデータ利活用の具体的な実現アプローチ、進め方についてMicrosoft FabricやAzure Synapse Analyticsといった“データ民主化”ソリューションの適用を含め、具体的なステップを紹介しつつ解説する。
1. 製造業における昨今のデータ利活用状況
1.1 「データ利活用」とは
まず、本稿で記す「データ利活用」とは、ただデータを集めて可視化・レポート化するだけではなく、実際にデータを利用して何らかの事業改善を行うことを指す。図1「データ利活用の定義」における「レベル3 予測分析」または「レベル4 意思決定支援」の取り組みのイメージだ。筆者の私見ではあるが、多くの製造業における取り組みはレベル1の可視化やレベル2の分析・洞察あたりにとどまっており、データ利活用として具体的な業務改善までは推進できていないのが現状である。

図1:データ利活用の定義
1.2 よくあるデータ利活用の方式
製造業では人手不足/属人化の解消、過剰在庫の抑制、製品改良に向けたプロセス分析など多岐にわたるテーマに対し、「データ利活用」により改善を図る取り組みが見られる。
代表的なところでは、以下のような利用例が存在する。
- 例1:設備における予知保全のためにOTデータ(IoT・センサーデータ)を集約し、機械学習で故障予兆を検知
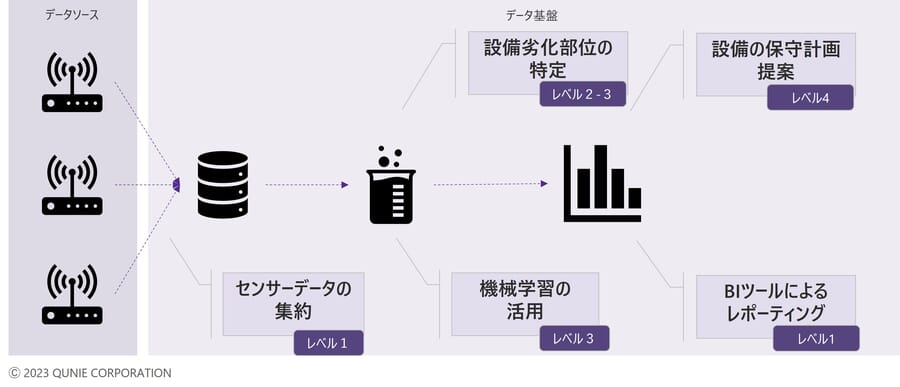
図2:OTデータ活用ユースケース
- 例2:拡張現実(AR)技術によってデジタル化・仮想現実化されたマニュアルをARゴーグルと組み合わせて活用し、リアルタイムに対処方法や示唆を表示
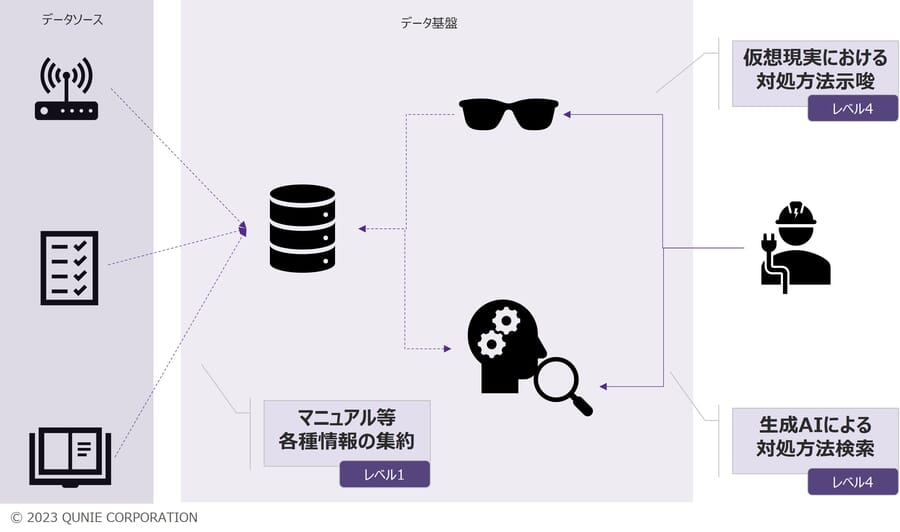
図3:データと仮想現実の複合活用ユースケース
1.3 データ利活用を阻む業界の課題
データの利活用により多くの課題を改善できそうなところは前述の通りであるが、一方でこれを満足に実現できている製造企業は決して多くない。
理由としては主に以下3点が考えられる。
●課題1:データの散在
各データがあちらこちらに散在しており、例えばオンプレミス環境内での利用に限定されたり、そもそもデータソースがExcelへの手動入力で自動化されていなかったりすることで、ユーザーが必要とするデータを容易に取得できない。
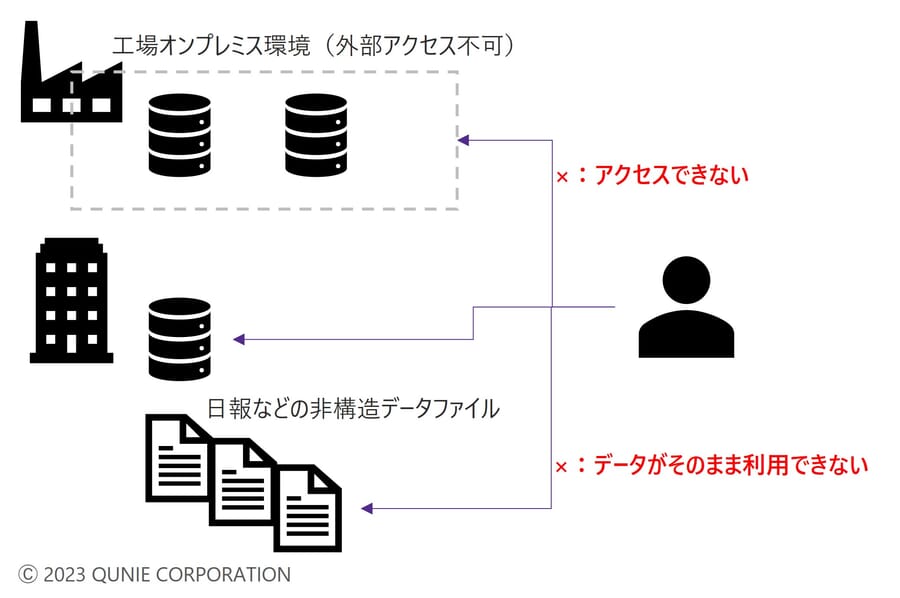
図4: 課題1「データの散在」
●課題2:外部ベンダーへの丸投げによるリードタイムの増大とデータ品質低下
課題1への対応を目指しデータを集約する際、従来のITシステムを利用したデータ収集方式では、外部ベンダーに依存することになるためシステム改修に時間がかかってしまう。または最終的に欲しい情報が得られず、データの可視化が業務の改善につながらない。
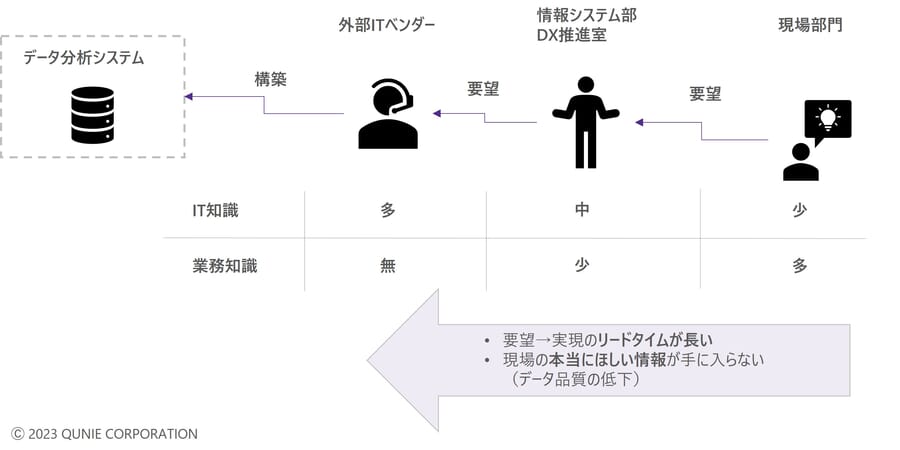
図5:課題2「外部ベンダーへの丸投げによるリードタイム増大とデータ品質低下」
●課題3:データ蓄積に時間がかかりすぎる
課題1への対応のためにあらゆるデータを集約しようとすることで、データ整備に多大な時間を要してしまい、成果を出す活用フェーズに入ることができない。
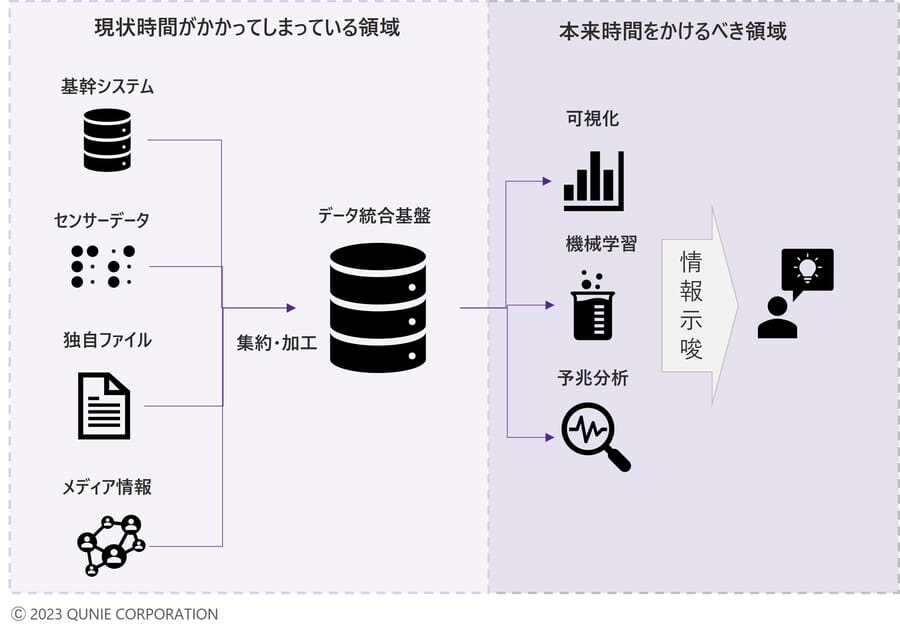
図6: 課題3「データ蓄積に時間がかかりすぎる」
上記のような課題により、DX推進施策として取り組むものの、効果を出す前に経営陣に見切りをつけられ施策からの撤退や見送りという結果に終わってしまっている場合があるのだ。
2. 今後あるべきデータ利活用の実現アプローチや実現手段
2.1 あるべき実現アプローチ
前述の課題を踏まえた上で、データ利活用のアプローチとして考慮すべき原則的な方針3点を下記に挙げる。
- 想定効果を明確にした上でのスモールスタート
- 内製化によるアジャイルな推進
- 現場社員を中心とした取り組み
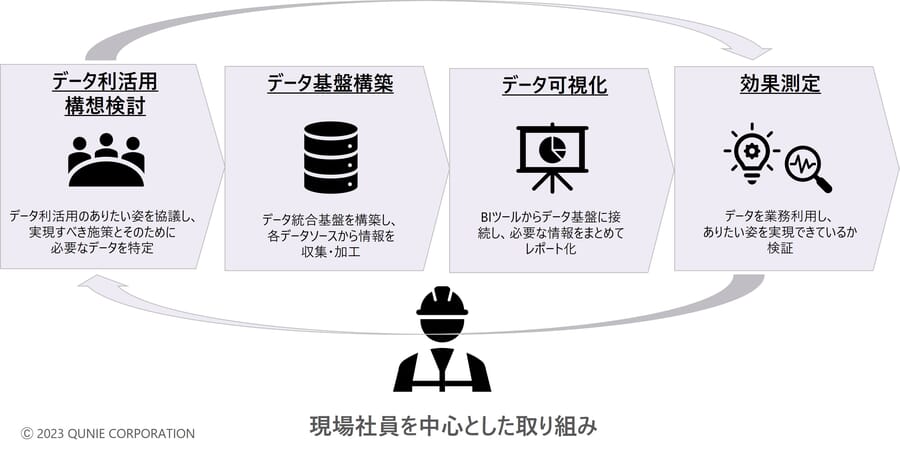
図7:「あるべき実現アプローチ」のイメージ
データ利活用施策の最初のステップとして、データを1つの場所に統合するデータ基盤の構築は必須であるが、目的を考えずにあらゆるデータを集約しようとすることは、ほとんどのケースにおいて悪手である。なぜなら、データ統合に係るコストや工数が増大してしまう課題3に行き着いてしまうからだ。また、超大規模なデータ量を有する基幹システムからのデータ収集は技術的な難易度も高く、課題2に陥ることにもなりかねない。
目的を明確にしないままにさまざまなデータを集約してしまった場合、一度で全ての結果を出せることはまれである。想定していたデータが不足していた、業務で別のデータもあわせて利用していた、特定のデータは制約があり他のデータと統合できなかった、など多岐にわたる原因により見直しが必要になる。そのような際は、対象のデータを最も理解している現場部門が主体となりデータ利活用の方針を修正し、必要なデータの見直し、または拡張、場合によっては想定ユースケースの再考までクイックに行う必要がある。そのためには、たとえ現場部門がデータウェアハウス(DWH)やプログラミングの知見を持たない“IT素人”であったとしても、データ基盤構築自体を内製化する必要があり、かつ継続的にアジャイルな取り組みとして組織レベルで活用を考えていく必要があると筆者は考える。具体的には図8のように、まずはスモールスタートで限定した範囲からデータ利活用を始め、分析レベルとデータ範囲を徐々に拡大していくアプローチを推奨する。
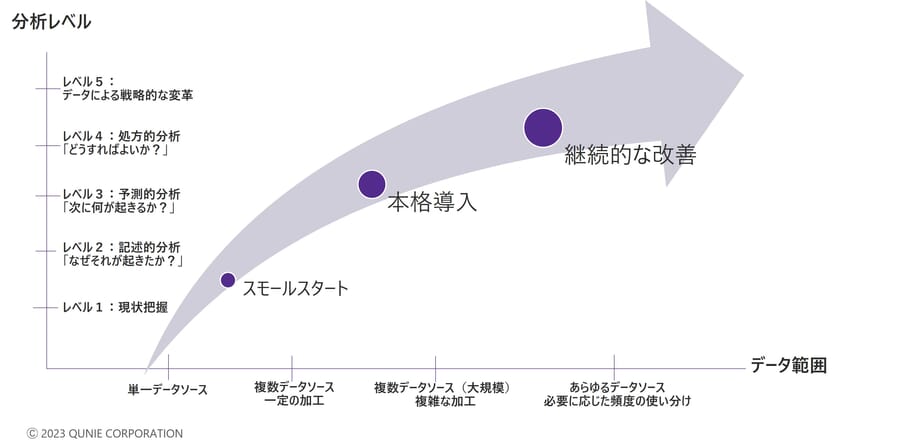
図8:スモールスタートからのアジャイルな取り組みのイメージ
2.2 IT素人が実現するデータ利活用の方策
“IT素人”によるデータ基盤構築を可能とするソリューションの1つとして、2023年5月開催 の“Microsoft Build 2023”にて発表された「Microsoft Fabric」がある。これはデータの移動からデータサイエンス、Real-Time Analytics、ビジネスインテリジェンスまで、あらゆるものをカバーする企業向けのオールインワン分析ソリューションである[1]。Microsoft Fabricを利用することで、GUI(グラフィカル・ユーザー・インターフェース)上で直感的なデータのつなぎこみが可能であり、可視化・分析を担うBIツール(Power BI)と同一画面で管理できることが魅力とされている。
本製品により、従来スペシャリストが必要であったデータエンジニアやサイエンティストの技術領域が一部簡易になったため、現場部門が自ら内製で取り組むことができるようになった。
例えばデータ基盤を構築する場合、技術的には以下のアプローチが必要となる。
- データ基盤構築:リソース作成、権限やネットワークセキュリティ設定
- データ収集・蓄積:データソースへのつなぎこみ
- データ加工:データクレンジング(ETL処理)、データマートの作成
- データ可視化:BIツールによるデータのレポーティング
- データ活用:機械学習やローコードによるデータの分析・利用
従来のPaaSやスクラッチのサービスを利用したアプローチの場合、特に1、2、3のデータエンジニアリング領域には多くの専門技術が必要とされていた。
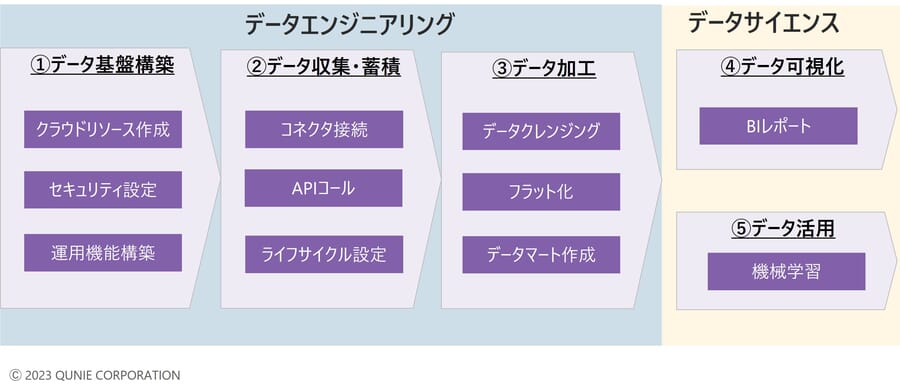
図9:データ活用における各工程に対する役割のイメージ
これがMicrosoft Fabricを活用すると、①~④を直感的な画面操作で実現できるため、適切なトレーニングを受ければITの専門知識を持たない現場部門でも実現することが可能と思われる。また、⑤の機械学習についても同ソリューション内で行えるため、専門的なデータサイエンティストとの意思疎通も容易となることが予想される。
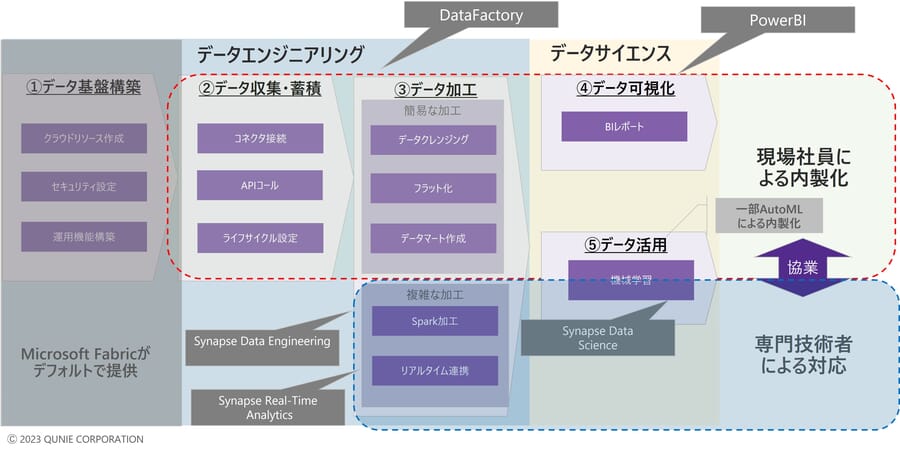
図10:Microsoft Fabricによる役割分担の分割イメージ
2.3 3つの課題への具体的な対応案
ここまでの記述から、1.3「データ利活用を阻む業界の課題」で述べた課題への対応策を以下のように整理することができる。
A) 課題1(データの散在)への対応
散在しているデータを利活用するには、データを1つの場所・サービスに集約すべき(=「統合データ基盤」を構築するべき)である。また、昨今のリモートワークなど場所を問わずにデータの利用を可能にすることを考えるとクラウド環境に統合データ基盤を配置することが望ましい。具体的にはMicrosoftの「Azure Synapse Analytics」やGoogle Cloud Platformの「BigQuery」のようなPaaS機能、または、先に紹介したMicrosoft FabricのようなSaaS機能を用いて統合データ基盤を構築することが有用である。PaaS機能を利用するとより細かなセキュリティ設定やスケーリングが可能であり、SaaS機能を利用するとよりクイックで直感的な操作が可能なため、要件に合わせてソリューションや製品を選択すべきであろう。
B) 課題2(外部ベンダーへの丸投げによるリードタイム増加とデータ品質低下)への対応
課題にて述べた通り、従来データ基盤を構築する際は、ITに関わる全ての領域において専門技術を持つ外部ベンダーが引き受けていたケースが多かった。しかし、機敏にデータ分析やデータ利活用を図っていく、あるべきアプローチ実現のためには内製化が不可欠である。これが、Microsoft Fabric (Data Factory、 Power BI)のようなデータ民主化ソリューションを用いることで、現場社員が一部のデータエンジニアリングやデータサイエンス領域を「内製化」することができれば、データ収集・加工とデータ可視化・利用のサイクルが加速し、より効果的な取り組みになっていくことが予想される。または、PaaS機能でのデータ基盤構築においても「Azure Synapse Analytics」などは画面から直感的にデータを収集・加工するGUI機能が備わっているため、最初から全て内製化するのではなく、難易度の高い初期構築をITベンダーやコンサルティング企業と進め、その中で自立して徐々に内製化を図っていくアプローチも考えられる。
C) 課題3(データ蓄積に時間がかかりすぎる)への対応
データ利活用のために必要なデータソースやあるべき期待効果は、必ずしも最初から完全に特定できているわけではない。そのため、最初から全てのデータを収集・可視化するのではなく、最小限のデータを組み合わせてスモールスタートで徐々に活用範囲を広めていくべきである、というのは先に述べた通りだ。その際、対象とすべきテーマのデータソースは、あらかじめサンプルデータと業務傾向を基に生成AIなどを利用し疑似作成するなどの工夫が考えられる。精度の高いサンプルデータからシミュレーションを実施することで想定効果を算出するなどして、短い期間で効果や実現性の高い施策を選定できれば、より効果的な「データ利活用」に結び付けられる確率が高まるであろう。
3. まとめ
会社全体として、または業務の現場にデータに関するノウハウのない製造業企業が、データ利活用を推進(=民主化)していくために必要な方向性を改めてまとめると次の通りである。
- 解決すべき課題を抽出し、データを用いてどのように業務改善を図るのかを明確にする。その際、事前にシミュレーションを行い、より効果・実現性の高い施策を選定する。
- 現場部門を中心とし、Microsoft Fabricのような直感的な製品を利用して可能な限り内製でデータを集め、少しずつ可視化を進めていく。
- 効果を測定し、収集データの拡大や業務改善にむけてアジャイルかつ継続的に取り組みを進め、「データ利活用」につなげる。
本稿が今後のデータ活用の進め方について迷われている方の一助となれば幸いである。
【関連情報】
データ利活用コンサルティングサービスについて
https://www.qunie.com/wp-content/uploads/2023/09/enterprise_solutions_theme_09.pdf
- [1] Microsoft(2023), “Microsoft Fabricとは”, https://learn.microsoft.com/ja-jp/fabric/get-started/microsoft-fabric-overview(参照日2023年8月18日)




あわせて読みたい
-

2023.06.13
製造業が取り組むべきIT/OTデータ活用の方向性
HANNOVER MESSE 2023から見えた将来像
バリューアディドサービス担当
- DX
- ERP
- サステナビリティ
- データマネジメント
- 製造業
-

2023.10.23
企業であまり使われていないPower Query(パワ…
Power Queryを活用した基本事項点検のススメ
小西 宏明
- DX
- データマネジメント
- 省人化
-

2023.08.22
デジタルトランスフォーメーション(DX)への第一歩 ~…
【第7回】成果を生むAIを導入するためには(特別編)
小倉 英一郎窪田 吉倫
- AI
- DX
- デジタルラボ
- プロジェクト管理
-

2023.03.16
Data Driven Retail
小売・流通におけるデータを起点とした継続的なビジネス改善手法
阪本 健一郎栗原 直樹
- DX
- SDGs
- サステナビリティ
- データマネジメント
- 小売・流通